Why did I create my own database?
I know this sounds crazy and, a few months ago, I never would have imagined such a feat or even raised such a possibility.

I have been developing software for a few years, and I have already used several database solutions in my projects, such as:
- MySQL
- PostgreSQL
- Redis
- MongoDB
- And many others …
Therefore, creating my own database was never a necessity in the projects that I participated in all these years, having always chosen some ready and specific solution for each case.
Until I started developing Vemto, my most recent project. Vemto is a code generator for the Laravel framework (a PHP framework), to facilitate the initial creation of Laravel applications, automating several things such as the generation of models, migrations, controllers, CRUD, the suggestion of Field Types, assembly of the Database Schema, etc.

I started planning Vemto at the end of 2019 and the development started in April 2020. It is a software strongly focused on processing relatively complex data. So, it would need a database (instead of something simpler like saving a JSON or YAML file).
Also, there was another very important factor:
The Template Engine that I developed for Vemto processes the logic directly in the template files.

Therefore, it was necessary that it was very simple to access related data, in a way similar to what ORMs do. For example, if I wanted to get all fields from a table I could do something like:
table.fields.forEach(field => {}) //…
Database choice …
As Vemto is a Desktop application developed with Javascript/Electron, I discarded solutions that need installation such as MySQL, MongoDB, etc. from the start. It needed to be a Built-in database.
At first, I considered using SQLite, a well-known relational database that I already have experience with. But during planning, I realized that I would need something that would offer a more Flexible Schema.
This would allow me to try and pivot the tool quickly while allowing me to quickly reach the competition (a very important requirement that I used in other parts of the software and I intend to talk about in another post).
I researched a lot at the beginning, tested several solutions, and the choice was with IndexedDB, as it is a database that comes practically ready for use in Electron (because of the Chromium used internally), it is fast and simple to use, in addition to having great flexibility, as it is a document-oriented database.
The headache …
Although IndexedDB is an excellent database, it was not the right choice for this project. And I only started to notice this around the second month of development, but at that moment, I decided to continue, since I had a lot of things ready.
Note to the Future: I had better stop and fix it soon, right?
I chose this database for its flexibility in data modeling, but I was wrong to disregard a very important detail:
Vemto handles Relational Data. A project has models and tables, a model or table has fields, a field has relationships with other tables, and so on …
And this weighs heavily on the choice because IndexedDB has two important characteristics: it is not relational, and it is completely asynchronous.
So when using it for a relational data model, you need to manually deal with things like:
- Async / Await Hell — As all operations are asynchronous, you are required to make a chain of asynchronous calls. For example, if you click on a button to delete a project, it must delete the related entities. To do this, you need to call an asynchronous method that uses an await to obtain related entities, and this forces all previous methods to be asynchronous (from the method called at the click of the button to the more internal methods).
- Relational operations — Simple things in relational databases like deleting a parent element, and automatically deleting children need to be handled manually. Also, it is very easy to generate N + 1 problems due to the lack of adequate indexing.
- Data pre-loading— Vemto data is organized in a way that can be used directly in the Template Engine, as explained previously. As it would be very complicated to work with this data asynchronously in the Template Engine, it was necessary to load all the relationships manually before sending them to the code generation.
In short, when I started working on the most complex parts, like the Schema Editor and the Initial Code Generation, I realized that the choice was not correct.
I was wasting a lot of time, in addition to generating numerous bugs and going crazy from stress. Seriously, I was going crazy and losing sleep over the “workarounds” that started to appear, damaging even the testability of the project.
I urgently needed a solution!
Looking for a solution …
Although I needed a relational database, non-relational document-oriented databases have some characteristics that I could not give up like the flexibility of the data scheme.
According to everything I realized so far, I needed a database with the following characteristics (all important):
- Support relationships — this includes things like indexes, CASCADE DELETE, constraints, foreign keys, etc.
- At the same time, everything else in the scheme that was not related to other entities would need to be completely flexible. I should be able to add new fields to the schema at any time, as well as in document-oriented databases (MongoDB, IndexedDB, etc.)
- I should be allowed to choose when to perform synchronous or asynchronous operations (asynchronous operations are also important since, in Electron, synchronous operations block the main process)
- There should be an ORM to facilitate the use, without the need to use a Query Language (mainly due to the use in the Template Engine)
- It should be Built-in and compatible with Electron, not requiring installation, and can be compiled together with the application (as well as SQLite)
In other words, I needed what we know as Hybrid Database, a little known category of databases, since use in common applications is quite rare.
More specifically, I needed an object-relational database (ORD) for Electron (something I didn’t know until recently).
I searched for weeks for a database with such characteristics. I found very little, and my last requirement, to be Built-in and compatible with Electron was the biggest obstacle to find something (I really believe that there was no database with all these requirements. If anyone knows one, let me know in the comments, please).
At this point, I was feeling quite pressured, as there was already a list of thousands of people registered on the Landing Page waiting to test Vemto, the months were passing and my schedule was very late, with Pre-Alpha postponed to September 2020 (Initially it would be in August).
In mid-June 2020, I had a sudden idea in a brief moment of rest.
Why not create a “parasitic” database layer, using a key/value database (like LocalStorage, Redis, etc.), and implement a hybrid database on top of it?
The idea seemed good, and at that moment I was able to visualize it “almost completely” in my head. I made some notes and created a prototype, but after focusing on it for a while, I thought it would be a lot of work and delay even more.
I decided to make a huge effort to finish the MVP with IndexedDB, at least to launch the Pre-Alpha version. It was very challenging and stressful, I had to make up most of the bugs with “lots of workarounds”, but I managed to release this version, which ended up attracting more people and making me even more desperate for a solution to the problem.

Developing the Database …
I couldn’t leave the software that way.
It would be impossible to maintain the code and beat the competitors promptly with so many difficulties, workarounds, and impaired testability.
So, in September I made the decision. I would finish implementing the database idea that I had in June and rewrite all the parts of the system that used IndexedDB to use this new database (with the provisional name that became definitive due to laziness: RelaDB).
Incredibly, finishing the database development was a very quick task, since I had a partially functional prototype.
If I knew I would have finished it before 😅
It took me about two weeks to finish the initial implementation. The entire development of the database was done through TDD (Test Driven Development), and I had a good idea of how the mechanisms should work.
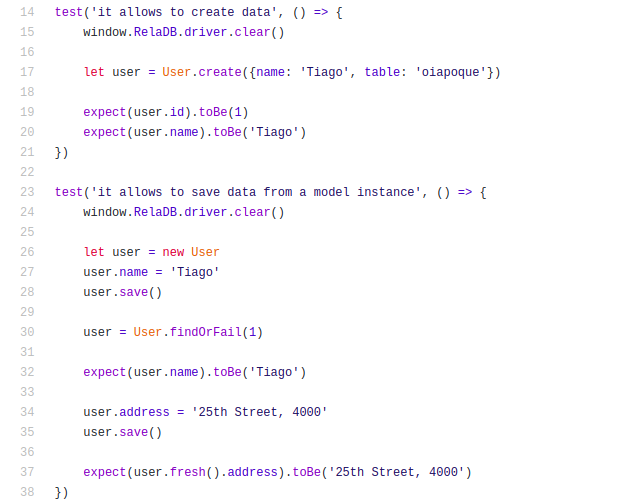
The database was created with an intrinsic ORM layer (strongly inspired by Laravel’s Eloquent ORM), thus facilitating its use.
The ORM currently supports “1:N” and “1:1” relationships, and “N:N” relationships have not been necessary so far so I left it to implement in the future (although the database internally supports them, since it is only necessary to create a Pivot table ).
It does not support query languages like SQL, as I decided to implement my own simple solution at the “low-level”, since I had well-defined requirements, and decided that the main interface for accessing the database would be the ORM itself, through Model classes.
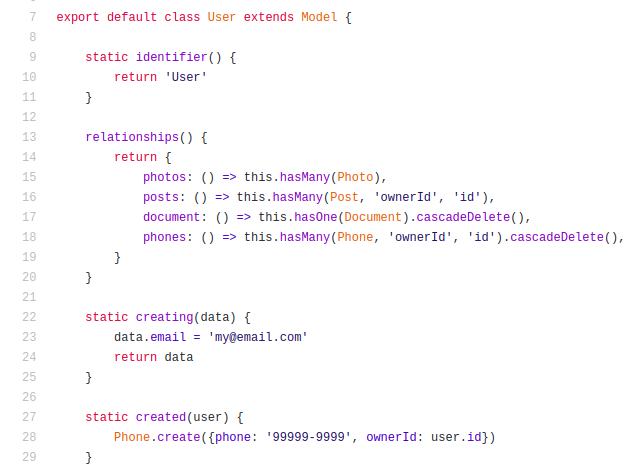
RelaDB is basically composed of three layers:
- The Storage Layer — following the original idea of a parasitic database, I ended creating a Storage layer with a behavior similar to key-value databases to store the basic low-level data. So, it is easy to write a driver to use an existing key-value database to be used to store the final data, but RelaDB has its own native Storage Logic
- The Database Layer — Here is the logic to control relationships, transactions, cache/buffer, constraints, tables data, etc. This layer takes care of structuring the database and saving it to the memory (permanent or not) using the Storage Layer
- The ORM Layer — The interface to access the database data
As it “can use” other key-value databases to store the basic low-level data, I developed it first by simulating a key-value database with arrays in memory.
It has the concept of “Drivers” (the Database Layer communicates with the Storage Layer using this driver), so, to adapt it to a new storage strategy or to a key-value database, just create a new Driver that has few lines of code (this makes it possible to use it with LocalStorage, Redis, or its own native driver).
With that in mind, I ended up creating my own storage strategy that saves the data to disk and then created a simple native Driver using this implementation.

In the short video below you can see an example of using the RelaDB ORM in an Electron application:
Changing the Database …
That part, yes, I would say it was very difficult!
I started refactoring code on September 28, 2020:
It took me about three weeks. They were very, very intense days.
Probably one of the most difficult tasks of my professional life, since I wanted to launch until November 2020, so it was huge pressure.
I’m tired to this day hahaha
I had to review practically all of the application’s code, a lot of it was rewritten and a lot of it was thrown away (mainly the manual tasks I mentioned earlier since now the database took care of everything automatically). I was also discovering several small bugs in RelaDB in the meantime that were being solved in parallel.
And then, on October 20, 2020, I finally did this monstrous merge (29,815 insertions and 8,352 deletions only refactoring).
My journey in developing my own database seemed to be nearing its end:
And finally, on October 29, much more relaxed and happy for the result of all the work, I launched Vemto officially:
Post-launch issues …
I had only two problems with the database after launch:
- Problem with numbers sorting — when performing a query sorting by a numeric field, for example, Project.orderBy(‘position’).get(), the database was sorting it alphabetically. It was a very quick bug to resolve.
- Performance problems — This one was very complicated, I only managed to finish solving it on November 15th, 2020, more than two weeks after the launch. The problem happened when there were many entities (models and tables) in a project. Despite being a complicated problem, only a few people creating big projects with Vemto complained. I needed to make several improvements in the way that RelaDB implements the queries and also created a Buffer/Cache layer. So the database performs all the heaviest operations directly on the Cache layer, which is extremely fast because it is in RAM, and then dispatches these operations as asynchronous transactions in the Background, through a separate process.
After solving these two, I had no more problems with the database.
Conclusion
Developing my own database was certainly the best decision I made in the context of this project. I would never do that if I was developing a common application, but in this case, it was a game-changer.
It is so simple to add new data and reflect it directly in the Template Engine, that I realized that the set of these two parts of the system is the reason to be able to launch new features quickly (in a few months, Vemto not only can solve most of the problems that competitors solve, as it brings a few more “little things”).
For this reason, I decided to keep the Database as Closed-Source for a while. But in the future, with it improved and properly documented (my documentation today is TDD), I intend to leave it as Open-Source.
I finish my adventure as a much more experienced developer than a few months ago. I never imagined that I would do that, but in the end, everything worked out.
Thank you very much for having accompanied me here, I wanted to write a lot more details but the text is getting too long.
I’m always posting my code adventures on Twitter. If you want to stay inside, please consider following me: https://twitter.com/Tiago_Ferat
Cheers and until next time!!
And a great new year for everyone!